Margaret Rule’s magnum opus was a prank so outlandish that scholars would debate it for hundreds of years. This magic trick was so controversial that it would be immortalized as a symbol of the feud between Cotton Mather and Robert Calef: she levitated to the ceiling in front of witnesses.
an introduction to the Salem witch trials by a literal banana
Why do humans and bananas alike get seduced into obsession with the events in Salem, Massachusetts, in 1692? It’s not the mystery of why twenty people were executed, and hundreds imprisoned, for a supernatural crime. It’s not the mystery of why everyone suddenly got tired of hanging witches in a matter of months. It’s not the mystery of why it was the last witch trial of its scale in the Western world. And it’s not the play written by a communist that everyone had to read in high school, which functions as a curiosity repellant.
In fact, as you will quickly learn if you begin to study Salem, the fascination lies in an ancient dispute between two men of Boston, one of whom had no involvement in the Salem witch trials at all. The first, the politically connected minister Cotton Mather, wrote the first history of the Salem witch trials in the immediate aftermath of the event, Wonders of the Invisible World, attempting to whitewash the affair and justify the executions. The second, the humble but successful weaver and merchant Robert Calef, did not much like this, and wrote the second history of the trials a few years later, More Wonders of the Invisible World. They came to very different conclusions.
Ever since, it has been a tradition for Salemheads to take a side in this dispute. The side you choose is important, because it informs all the decisions you will arrive at about the import of each piece of evidence. Your judgments about every question arising from the tragedy will have curious relevance to the matter of which man you back in this antique beef.
The picture that emerges is that a placebo pill has almost no effect when administered by researchers who do not care about the placebo effect, but the exact same pill has an enormous effect larger than all existing treatments when administered by a researcher who really wants the placebo effect to be real. The most parsimonious explanation is that it is the research practices, rather than the placebo.
Introductory summary: The current scientific consensus is that the placebo effect is a real healing effect operating through belief and suggestion. The evidence does not support this. In clinical trials of treatments, outcomes in placebo and no-treatment arms are similar, distinguishable only in tiny differences on self-report measures. Placebo-focused researchers using paradigms designed to exploit demand characteristics (politeness, roleplaying, etc.) produce implausibly large effects, in many cases larger than the effect of fentanyl or morphine, but these studies measure response bias on self-report outcomes (at best). There is no evidence that placebos have effects on objective outcomes like wound healing. Three sources of evidence purport to show that the placebo effect is a real, objective phenomenon: brain imaging studies, the alleged involvement of the endogenous opioid system or dopaminergic system, and animal models. But the brain imaging studies do not demonstrate an objective effect, but are rather another way of measuring “response bias,” as subjects are capable of changing these measures voluntarily. Studies that claim to demonstrate the involvement of the endogenous opioid system suffer from replicability issues, with most positive results coming from a single laboratory genealogy; other laboratories produce conflicting results. Animal models also suffer from replicability issues, such that the highest-quality research is least likely to produce a placebo effect in animals. Even research designs that do produce a conditioned “placebo effect” in animals cast doubt on the involvement of the endogenous opioid system. In the era of open science, there has been no large-scale, multi-center, preregistered attempt to address the placebo effect in animal models or the involvement of the endogenous opioid system. The one adequately powered preregistered attempt for the dopaminergic system in humans produced no effect. Although placebo and “mind-cure” beliefs are widespread, the most parsimonious interpretation of the evidence is that the “placebo effect” is not a real healing effect, but a product of response bias and questionable research practices. The true power of the placebo is as a blind.
This appendix to “A Case Against the Placebo Effect” reviews the studies in the Sauro and Greenberg (2005) meta-analysis on the effect of opioid antagonists on placebo analgesia, in alphabetical order. Next, the relevant sizes of the study arms for each study are provided. Finally, research into the “placebo effect” in depression is reviewed.
An explanation of why tricks like priming, nudge, the placebo effect, social contagion, the “emotional inception” model of advertising, most “cognitive biases,” and any field with “behavioral” in its name are not real
by a literal banana
Nothing Works That Way
Back in 2014, Kevin Simler published a provocative essay on the nature of advertising called “Ads Don’t Work That Way.” I imagine most people reading this have read it, and if not they really should read it in its entirety, but I’ll summarize as a reminder. Some advertising works in really boring ways, basically reminding potential customers that the product exists. Simler gives the example of drain cleaner; I think this is also how most fast food advertising operates. But there is also a more psychological theory of advertising, which Simler calls “emotional inception,” in which advertisers create a Pavlovian association between their products and positive emotions or other desirable attributes. In the inception theory, our little brains are extremely malleable and vulnerable to such associations, and we can’t help but associate soda with happiness, sweetened fruit snacks with being a good parent, etc.
Simler does not think this is how advertising works. His theory, which he calls “cultural imprinting,” ascribes more rationality and less pathetic malleability to our interactions with advertisements. In this model, brands create cultural messages with their advertising dollars, so that buyers know what message they can expect to be sending when they purchase products that are consumed socially. One of his major examples is beer branding, and he predicts the Bud Light advertising debacle of 2023 with incredible accuracy with one bit flipped:
If I’m going to bring Corona to a party or backyard barbecue, I need to feel confident that the message I intend to send (based on my own understanding of Corona’s cultural image) is the message that will be received. Maybe I’m comfortable associating myself with a beach-vibes beer. But if I’m worried that everyone else has been watching different ads (“Corona: a beer for Christians”), then I’ll be a lot more skittish about my purchase.
For me, this was an introduction to a new way of thinking: perhaps those phenomena that popular media and official science explain with mysterious psychological effects on weak brains – automaticity – might actually be better explained by rational processes. The rationalist community centered on LessWrong, which was an important influence on my thinking, often focused on cognitive biases, taking the work of Daniel Kahneman and even priming studies seriously as evidence for the structures of human reasoning. To their credit, these associations do not seem to have been edited out of their corpus since the replication crisis in social sciences began to demolish the automaticity literature. An important motivation of the rationalist movement, as I saw it, was that we were all very irrational beings, and had to struggle to become more rational. My argument in this essay is that we are actually very rational, but managed to convince ourselves, for a variety of (perfectly rational) reasons using a variety of tactics, that we were helpless idiots.
Ego Depletion, or Thinking Fast and Slow, The Foundation of Priming
I take the term “automaticity” from the priming researcher John Bargh, famous for “proving” that simply solving word scrambles with elderly-related words like “wrinkle” or “Florida” caused undergraduates to walk as slowly as old people. (Fewer people know that he also “proved” that the same primes cause people to be more forgetful!)
Let’s briefly look at what Daniel Kahneman had to say about priming research in his book Thinking Fast and Slow:
When I describe priming studies to audiences, the reaction is often disbelief. This is not a surprise: System 2 believes that it is in charge and that it knows the reasons for its choices. Questions are probably cropping up in your mind as well: How is it possible for such trivial manipulations of the context to have such large effects? Do these experiments demonstrate that we are completely at the mercy of whatever primes the environment provides at any moment? Of course not. The effects of the primes are robust but not necessarily large. Among a hundred voters, only a few whose initial preferences were uncertain will vote differently about a school issue if their precinct is located in a school rather than in a church—but a few percent could tip an election.
The idea you should focus on, however, is that disbelief is not an option. The results are not made up, nor are they statistical flukes. You have no choice but to accept that the major conclusions of these studies are true. More important, you must accept that they are true about you. If you had been exposed to a screen saver of floating dollar bills, you too would likely have picked up fewer pencils to help a clumsy stranger. You do not believe that these results apply to you because they correspond to nothing in your subjective experience. But your subjective experience consists largely of the story that your System 2 tells itself about what is going on. Priming phenomena arise in System 1, and you have no conscious access to them.
He was also a believer, at the time, of another important phenomenon, “ego depletion,” which, as I will explain, is the foundation for priming-style automaticity and in fact most of the phenomena that I label as examples of automaticity:
A series of surprising experiments by the psychologist Roy Baumeister and his colleagues has shown conclusively that all variants of voluntary effort—cognitive, emotional, or physical—draw at least partly on a shared pool of mental energy. Their experiments involve successive rather than simultaneous tasks.
Baumeister’s group has repeatedly found that an effort of will or self-control is tiring; if you have had to force yourself to do something, you are less willing or less able to exert self-control when the next challenge comes around. The phenomenon has been named ego depletion. In a typical demonstration, participants who are instructed to stifle their emotional reaction to an emotionally charged film will later perform poorly on a test of physical stamina—how long they can maintain a strong grip on a dynamometer in spite of increasing discomfort. The emotional effort in the first phase of the experiment reduces the ability to withstand the pain of sustained muscle contraction, and ego-depleted people therefore succumb more quickly to the urge to quit. In another experiment, people are first depleted by a task in which they eat virtuous foods such as radishes and celery while resisting the temptation to indulge in chocolate and rich cookies. Later, these people will give up earlier than normal when faced with a difficult cognitive task.
Ego depletion is an embarrassing moment for science: hundreds of experiments “replicated” an essentially fake phenomenon, and it took the organized efforts of preregistered ManyLabs-style replication police to put it to rest. (I should mention that one of several large replication attempts led by a pro-ego-depletion researcher managed to find a small effect, but this needs to be weighed against the other large replication efforts, the most recent led by another pro-ego-depletion researcher, Kathleen Vohs, that failed to find any such effect, and against the general silliness of the project.)
But why did they fight so hard for ego depletion? It’s because ego depletion is the foundation upon which priming and other automaticity effects rest, and if it falls, they have nowhere to stand, as outlined by Bargh:
Tice and Baumeister concluded after their series of eight [ego depletion] experiments that because even minor acts of self-control, such as making a simple choice, use up this limited self-regulatory resource, such conscious acts of self-regulation can occur only rarely in the course of one’s day. Even as they were defending the importance of the conscious self for guiding behavior, Baumeister et al. (1998, p. 1252; also Baumeister & Sommer, 1997) concluded it plays a causal role only 5% or so of the time.
Given one’s understandable desire to believe in free will and self-determination, it may be hard to bear that most of daily life is driven by automatic, nonconscious mental processes-but it appears impossible, from these findings, that conscious control could be up to the job. As Sherlock Holmes was fond of telling Dr. Watson, when one eliminates the impossible, whatever remains-however improbable-must be the truth.
For priming to exist as an important phenomenon, we must spend most of our time basically unconscious, or in “System 1” as Kahneman puts it, mere puppets of our environment, until some rare challenge forces us to wake up briefly to deal with it, so that we may go back to sleep.
Bargh and Kahneman are adamant that we can’t trust our experience, because our experience by necessity excludes the 95% of the time we spend as unconscious automatons, and that we must trust science instead. This is similar to the promotion of the “emotional inception” theory of advertising, which remains popular in marketing science, such as it is.
Here’s a bit of such science from Shiv, Carmon, and the legendary Dan Ariely, for flavor, which unites priming, “emotional inception” marketing, and the placebo effect, which will be the the subject of the next section:
In this experiment, participants first consumed SoBe Adrenaline Rush (a drink that claims to help increase mental acuity on its package) and then solved a series of puzzles.
Remember SoBe? The researchers told the subjects that they would be drinking this mind-improving beverage, and then had the gall to give them a form explaining that they were charging the subjects’ university accounts for the privilege of drinking it. Half of the subjects were charged the regular $1.89 price; half were told that they were only charged 89 cents, explaining it had been purchased with an institutional discount. What these experimenters “found,” was that if they had the subjects rate their “expectancies” for how much the SoBe would improve their mental functioning, thereby incepting such expectancies, the subjects who got it at a discount solved only 5.8 word jumbles, compared to 9.9 in the full price group. That is, simply drinking discount energy drink caused these poor subjects placebo brain damage to a fairly significant degree.
The example they give of a word jumble is “TUPPIL, the solution for which is PULPIT.” They allowed subjects 30 minutes to solve as many puzzles as possible; as the best group mean performance was about 10, they were taking about three minutes per word at the fastest. When I’ve looked up six-letter word jumble puzzles in the literature, they seem to allow about 20 seconds for subjects to solve them, but perhaps these were unusually hard puzzles.
That is how priming is supposed to work: we are automatons going around in our sleep, and our performance on a simple puzzle can take a major hit simply by being informed that our drink was bought at a discount. We are infinitely vulnerable to our environment, to suggestion, to parlor tricks, that we can experience a major loss of intellectual ability, walking speed, memory, just by exposure to some infinitely subtle stimulus.
From an evolutionary perspective, it seems like a bad design. You could be out there hunting with your elderly father, and suddenly you look at him and start walking slower and can’t remember what you were doing. You’re at your job and see an acronym BIB and start crawling around on the floor. You’re at the grocery store and you buy ice cream not because it is delicious and enjoyable but because the packaging primed warm emotional feelings and you subconsciously need to cool down. You find out that your prescription Adderall was bought with an insurance discount and suddenly lose 40% of your mental capacity.
It’s not just that the relevant science is fabricated, or p-hacked, or uses meaningless measures or flexible measures, although the prevalence of such things does cast doubt on their evidentiary value. It’s that we should have been more skeptical from the start. The automaticity hypothesis is just as woo as spoon bending and precognition, and we should demand as extraordinary evidence for automaticity as we learned to demand regarding the others. See, e.g., Daryl Bem’s 2011 paper purporting to find evidence of clairvoyance, which may have played a role in instigating the replication crisis, and the history of the scientific investigation of spoon bending.
The spoon benders actually had to make a show of bending a spoon. Regarding automaticity, all we seem to ask is that someone wrote a paper claiming they bent a spoon.
Pre-Post-Erous!
Most people take the placebo effect, as “demonstrated” in the SoBe study, for granted. We “know” that placebo pills heal people; maybe we even “know” that a placebo can still heal if it is openly labeled as such, or that more expensive placebos are more effective. If the placebo effect were not real, why would large medical trials of new drugs have to randomize subjects to a placebo condition? And why would they find big improvements in the placebo condition?
I will argue that we should put healing placebos into the “automaticity = woo” mental bucket. Placebos don’t work that way either.
The first piece of the puzzle is how placebos actually function. Placebos have a perfectly valid job in randomized controlled trials: they are an attempt at mimicking the “noise,” or natural variation, from every aspect of the treatment process other than that believed to be efficacious, including time. Blease et al. explain the distinction:
Before reviewing findings from OLP studies, it is crucial to clearly demarcate between two distinctive uses for the term placebo. First, is the usage of placebos in RCTs. Here the term is often understood to refer to a certain kind of ‘thing’ (eg, saline injections or sugar pills). Strictly speaking, this interpretation is incorrect: instead, placebos in RCTs ought to be conceived as methodological tools since their function is to duplicate the ‘noise’ associated with clinical trials including spontaneous remission, regression to the mean, Hawthorne effects and placebo effects. Properly understood, then, these types of placebos are deployed as controls that are specifically designed to evaluate the difference—if any—between a control group and a particular treatment under scrutiny. Ideally, in RCTs, controls should mimic the appearance and modality of the particular treatment or medical intervention under investigation. In contrast, placebos in clinical contexts are interventions that may be intentionally or unintentionally administered by practitioners either with the goal of placating patients and/or of eliciting placebo effects.
Many conditions are episodic or vary in severity, and starting from a bad time, the problem will often get better after a while on its own. When people talk about “regression to the mean” as an explanation for the placebo effect, this is what they mean. It’s mostly the “pre-post” comparison, as hinted in my title for this section. This effect can be enhanced by something called “eligibility creep” in dermatology: in an effort to include more subjects, researchers may exaggerate potential subjects’ condition at the outset of the study, so that an accurate measurement without exaggeration at the end will show a spurious improvement.
The second piece of the puzzle is that placebo effects compared to no treatment are small. Not just “small” in the meaningless sense of effect size, but too small to be noticeable or to make any clinical difference. For pain, a large meta-analysis found the mean placebo effect to be about 3.2 points on a 100-point scale, too small to matter. Similarly, the most recent meta-analysis on the placebo effect in depression found similar results, an effect size of .22, which is smaller than the effect of antidepressants over placebo, about .3, which translates into about 1.7 points on a 52-point scale and is too small to be clinically relevant. This is the case even though subjects in “no treatment” groups may have an incentive to exaggerate their symptoms in order to receive treatment, whereas those on placebo believe they are receiving treatment and have no such incentive. Still, effects are tiny, so tiny as to be meaningless in real life, and definitely tiny enough to turn out to be nothing at all with better methods.
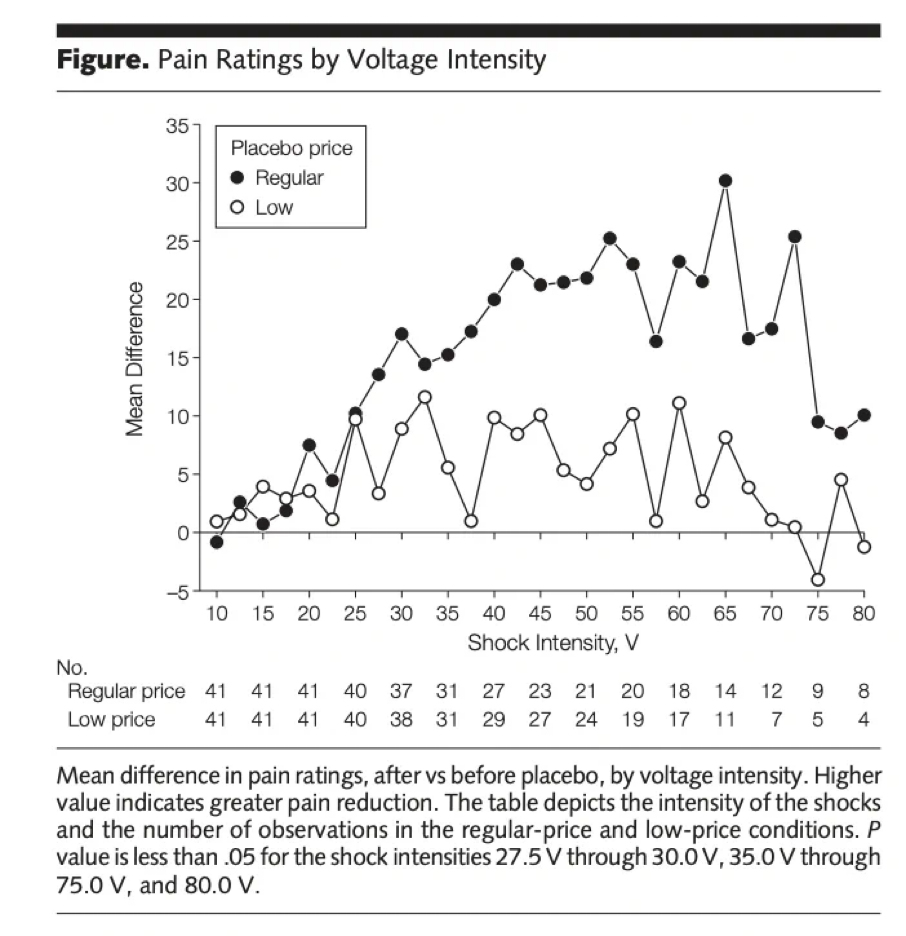
The third piece of the puzzle is that we can’t trust studies that claim to find large placebo effects, for the same reason that we can’t trust priming studies. Here’s a figure from a paper by Waber, Shiv (from the SoBe paper), Carmon (same), and Dan Ariely, demonstrating a massive effect of more expensive placebos on pain from electric shock (both are placebos, the dark one is the normal price and the light one is discount):
We see effects in the “regular price” condition as high as 30 points on a 100-point scale, and often in the 20s, several times higher than the 3.2 point effect on pain we saw earlier, and certainly clinically significant. This level of pain relief would really matter. I was able to find a more recent study using similar methodology, though not labeling itself a replication, that found placebo effects of zero, one, and three points on a one hundred point scale in similar conditions, respectively. These seem much more realistic, and when combined with the meta-analysis results, indicates that the study that got a huge result is a major outlier.
I do not think, contra Kahneman, that we “have no choice” to accept that such effects are real. Even without knowing about all the irregularities of this particular experiment (such as lack of IRB approval for shocking human subjects and deceiving them about pain medication), we should recognize how extraordinary these claims are, and demand appropriate evidence for them, not just one team’s word that such experiments even took place.
Enter the Nudgelords
Nudge is just priming.
If there are stylized sculptures of waifish humanoids in a room, subjects will eat four fewer blueberries. If you sign at the top, you’re more honest than if you sign at the bottom. It’s priming, as a service.
Nudge studies aren’t real and don’t replicate. When they’re attempted in the real world, the effects are much smaller than in the academic studies, and the effective so-called nudges tend to share a curious feature: they operate on rationality rather than automaticity. For instance, one of the most effective “nudges” is apparently for the government to send clearly-worded letters explaining what they want people to do. That seems more like common sense and respect than a “nudge” to me, but I’m not a Nudge Professional.
“Behavioral” anything (economics, finance, etc.) tends to reduce to automaticity explanations.
I won’t spend much time on Nudge because it’s literally the same thing as priming – the same model of reality, the same experiments, often the same researchers, just using a different word.
Cognitive Bias Parlor Tricks
I can’t go over every cognitive bias individually in this format, but I will give a basic pattern of how I think “cognitive biases” are produced as academic products:
First, an experiment or test is devised that people perform “poorly” on in some specific manner or dimension. It could be a list of choices of lotteries with different payoff structures (see e.g. this investigation of problems with a celebrated Kahneman mathematical model and associated experiments), or the famous demonstration of the “endowment effect” many of us experienced firsthand, in which we are given a unique little gift, like a mug, and then shamed for not being “rational” enough about its value when invited to trade it for somebody else’s gift.
Second, this little experiment, and variants of it, are generalized to the entirety of human behavior. Perhaps a study on “conversation” involves strangers chatting in a laboratory about the answers to trivia questions, and the researchers find that this has no effect on accuracy. This may be generalized to a proposition like “conversations serve no purpose” in general, perhaps a “conversation bias” can be introduced, and people can feel smug for not liking meetings at work.
Thus, we have scientific confirmation that a “bias” exists. This is often confusing, because, for example, if the “endowment effect” obtained under normal circumstances, markets would grind to a halt and not be able to function, because everyone would value what they already own more than anyone who didn’t own it.
One solution to this kind of problem, both in cognitive bias and priming research, is to say that you found a “boundary condition” instead of that you failed to find the effect. “Boundary conditions” are a similar kind of cope to “mediator” or “subgroup” analysis, especially in small studies not powered to detect them.
Overall, I think rationality is a better starting assumption for human behavior, and we should demand a great deal of evidence for an important, widespread departure from rationality.
Which of your favorite biases survived the replication crisis, and do they generalize?
Can You Catch Stupid?
“Social contagion” is the idea that behaviors spread through human groups like infections. Trivially, the spread of technologies like hybrid corn or mobile phones can be modeled like epidemics. The only “automaticity” aspect is the tendency to take the metaphor seriously, as if people were really affected by “social contagions” in the same unconscious, unfree way as by germs.
Some phenomena that have been proposed to be socially contagious are suicide, obesity, quitting smoking, and (as a bit) acne, headaches, and height. The latter three are a bit in the sense that they use similar methodologies as the social contagion literature to demonstrate that homophily, the tendency for similar people to cluster in social groups, accounts for most, if not all, of the supposed “social contagion.” A more advanced method is to use time lags, as if time-lagged obesity weren’t as much a factor of homophily as snapshot-in-time obesity.
However, researchers essentially never try to distinguish germ-type “contagion” from social learning. I think our starting hypothesis should be that behaviors that spread in the population arise from social learning, rather than from a mysterious unconscious process of thoughtless copying. Human copying is anything but thoughtless. Copying is an important form of creativity. Nonhuman animals can copy but a tiny fraction of our behaviors, even if we sometimes like to pretend they are capable of stealing our cool cottagecore aesthetics by dressing them up in sick outfits.
People share and copy, but social contagion doesn’t work that way.
The Clockwork Universe With Clockwork People
An extended excerpt from the phenomenologist Gian-Carlo Rota, better known in mathematics for his work in combinatorics, on the fading myth of our time:
The theory of myths asserts that every civilization is ultimately characterized by the series of myths it believes in. These “working myths” are myths that that civilization is not aware of at all. They are not verbalized. The moment such a myth is out into words, it’s no longer something that people authentically believe in. It can now become a subject of discussion. So, as time goes by, a given myth that was universally believed in suddenly cracks and becomes doubted. At such a moment, the members of that civilization split into opposing camps: those who say “Yes, it’s so” and those who say “No, it’s nonsense.” And then the myth will fade, and finally it’s viewed as untenable except by a small group of people, who keep it as a superstitious belief.
….What I’m working towards is that not too long ago, there was a particular myth, universally believed, that in our time is being verbalized, which is the first stage towards its fading. A lot of phenomenology is a discussion and critique of that particular myth.
What is that myth? It’s the myth of the clockwork, the myth of mechanism. It’s the idea that you can explain every phenomenon causally, by finding an underlying mechanism. It has been strongly believed in for a few hundred years. It had its heyday in the nineteenth century. It’s very simple: understand how the wheels work and you’ll understand everything. This went on and on, and that’s the myth that’s cracking in our time. I’m not in any way implying that mechanisms are bad, or that there are no mechanistic explanations. Certain phenomena can certainly be explained mechanistically. But there are other phenomena that do not have such an explanation. When you say this nowadays, tempers run high. Someone will point a finger at you and say, “You are an irrationalist! Either you believe in mechanism, or else you are irrationalist! Either a marble is red or it’s blue! Nothing in between!” But the phenomenological answer is that it is in no way irrational to deny a mechanistic explanation. We are not denying other modes of explanation which are logical and coherent, but just not mechanistic.
Those who will accuse us of irrationalism have an extremely narrow view of rationalism, a view that scientists have abandoned a long time ago. Ever since quantum mechanics came to be, and quantum mechanics is probably the greatest scientific idea of this century (n.b. the 20th -ed.), you can kiss goodbye to causal explanation. It’s very unfortunate that we still do not really understand quantum mechanics. Feynman used to stress that: quantum mechanics works, but there is something so mysterious about it, so completely different from anything we’ve thought about, that no one has succeeded in explaining it. But that works as our ally now. If someone tries to propose causal explanation as the scientific paradigm, we can say, “Phony baloney, science doesn’t work that way anymore! They gave that up decades ago.” Science is far more sophisticated. The strictly marble-like causal explanation is something that’s been thrown out of the window.
Science doesn’t work that way anymore, but few have gotten the message. Phenomenology proposes a different form of causality from the “marble-like” version, one based on conditions of possibility, a “Fundierung” relationship of things being founded on each other in the sense of allowing each other to come into being and be perceived as such. It is outside my scope to attempt an explanation at length, but this model of the world is not a woo model. It is a richer model, a more realistic model, and a model more in accord with careful observation of the world than the received marble-like model that has allowed us to accept so much silliness.
The automaticity theories named here are holdovers from the fading myth of the clockwork universe, of clockwork people. The myth began to be named by the end of the 19th century (by William James at least, who also named the related Religion of Healthy-MIndedness that is still with us today). I hope by naming a more specific incarnation of the myth here that I can promote its thematization so that it can continue to fade. A science of ourselves cannot be established by dressing woo in lab coats, clipboards, and the mathematical ideas of an antique physics.
I invite anyone to be the Lakatos to my Feyerabend, and present Here’s Why Automaticity Is Real Actually, as mine is an extreme case and does not pretend to be a measured, balanced examination of the subject. I would not recommend that anyone superstitious attempt this project, however, for obvious reasons: if priming were true, such an effort could prove lethal.
Concerning placebos and the “placebo effect,” there is a distinction that I have struggled to articulate, a distinction I have also noticed highly intelligent humans failing to make. I recently found an excellent explanation of the distinction in a paper questioning the meaning of recent “open-label placebo” trials, and thought it was worth a short piece explaining why it’s important.
Here is the distinction as the authors put it, with citations removed:
Before reviewing findings from OLP studies, it is crucial to clearly demarcate between two distinctive uses for the term placebo. First, is the usage of placebos in RCTs. Here the term is often understood to refer to a certain kind of ‘thing’ (eg, saline injections or sugar pills). Strictly speaking, this interpretation is incorrect: instead, placebos in RCTs ought to be conceived as methodological tools since their function is to duplicate the ‘noise’ associated with clinical trials including spontaneous remission, regression to the mean, Hawthorne effects and placebo effects. Properly understood, then, these types of placebos are deployed as controls that are specifically designed to evaluate the difference—if any—between a control group and a particular treatment under scrutiny. Ideally, in RCTs, controls should mimic the appearance and modality of the particular treatment or medical intervention under investigation. In contrast, placebos in clinical contexts are interventions that may be intentionally or unintentionally administered by practitioners either with the goal of placating patients and/or of eliciting placebo effects.
Blease, C. R., Bernstein, M. H., & Locher, C. (2020). Open-label placebo clinical trials: is it the rationale, the interaction or the pill?. BMJ evidence-based medicine, 25(5), 159-165.
On the one hand, there is the use of placebos in randomized controlled trials, in which the point is to “duplicate the noise” that’s likely to exist in the treatment group. On the other hand, there are hypothesized “placebo effects” that may take the form of real healing, which is not at all the same.
For a specific example, just because antidepressant trials result in enormous placebo effects does not mean that depression responds to placebo in real life. The proper conclusion to the size of placebo effects in these trials is that the measurement of depression is extremely noisy, to put it in the most polite way.
While true “placebo effects” of the healing variety may exist, it’s worth engaging with these authors’ concerns over how that may be demonstrated, particularly in open-placebo design trials in which the hope is to pave the way toward ethical placebo treatment. The choice of control is particularly tricky; for example, as with antidepressant treatments, simply using “treatment as usual” or “wait list” as controls likely inflates apparent effects. True blinding requires a great deal of subtlety and effort in research design.
In summary: noise isn’t healing.
Now we can all pretend that we knew it all along and never mistook the one for the other!
As a banana who lives among humans, the sacred beliefs of humans interest me a great deal. By “sacred beliefs” I mean beliefs that are widely shared and have a high level of emotional vehemence surrounding them, preventing them from being questioned, except by trolls. Usually the goal of trolling is to provoke a defensive reaction, so sacred beliefs can often be brought into visibility by effective trolls.
This is not a troll. I am deadly serious and I think this is extremely important.
The sacred belief I am addressing here seems to have originated in the late twentieth century, and blossomed into ubiquity in the twenty-first century. It concerns “mental health,” and has multiple parts. First, it is the belief that mental illnesses are real diseases, just as serious as ordinary medical diseases, and no more the fault of the sufferer. Responses to trolls like “depression is a choice” bring this belief into visibility. Second, it is the belief that shame and stigma prevent people from seeking help for mental illness. Third, and the only part of the sacred belief system that concerns me here, is the belief that effective treatments for mental illnesses are available, and that once a person overcomes shame and stigma to seek help, the sufferer stands a good chance of getting meaningfully better.
Here, I will focus on one of the most common mental health problems, depression, known in current medical jargon as Major Depressive Disorder. Further, I will focus on the two gold-standard treatments for depression, generally considered to be the most effective treatments: antidepressant medication and cognitive behavioral therapy. I hope to eventually address treatments for two more conditions, schizophrenia and substance abuse disorder, but those will have to wait for future installments.
Medicine has always existed in some form, and there have always been people who claim to have been cured by the techniques of the day, going back at least as far as recorded history and almost certainly much further. But the evidentiary technique that is supposed to separate modern medicine from the misguided attempts at medicine of the human past is the double-blind placebo-controlled trial. Individual trials may lack statistical power and suffer from publication bias and other quality problems, however, so the true best evidence is probably the large meta-analysis of placebo-controlled trials.
Meta-analyses raised concerns about the efficacy of antidepressant medications almost as soon as they began, but I will focus on a recent large meta-analysis, Cipriani et al., 2018, that received a great deal of attention. Cipriani et al. interpreted their findings thus: “All antidepressants were more efficacious than placebo in adults with major depressive disorder.” This seems like good news, but the bad news was how much more efficacious the drugs were. They report an effect size (standardized mean difference compared to placebo) of .30. This effect is considered “small” according to tradition and current guidelines, but how small is small?
Most antidepressant trials use one or both of two measurement instruments: either the Hamilton Depression Rating Scale (HAM-D or HDRS), a 52-point rating scale applied by researchers or doctors to judge how depressed a person is, and the Beck Depression Inventory, a self-rating scale. (Note: the HAM-D may sometimes be referred to as the HAM-D-17 or HDRS-17 because it has 17 items, but it is a 52-point scale, as each item may score multiple points toward the total.) An effect size of .3 corresponds to about two points on the 52-point HAM-D scale, which, on the face of it, if you happen to read the instrument itself, is not much. This is not even taking into account that methodological issues and questionable research practices may account for most or even all of the apparent superiority over placebo. A difference smaller than seven points may not even be detectable by clinicians. Interestingly, a Cochrane review of Dance and Movement Therapy rejected the therapy as not having clinical significance because it only reduced depression scores by slightly over seven points above (psychological) placebo, which was less than 25% of baseline in the relevant studies. By this standard, since HAM-D scores in the antidepressant trials were generally in the mid-to-high 20s, at least 6 or 7 points would be necessary to achieve clinical significance. The upshot is that antidepressants “work” to a degree that is much too subtle for anyone to notice, which is bad enough, but also increases suspicions that they don’t work at all.
There are many branching paths of cope that have been explored for the seemingly devastating result that antidepressants are all pretty similar to each other and move a 52-point depression scale by two points at best compared to placebo. One is that the problem is the scale. Maybe using a self-report scale would better capture the healing effects of antidepressants? However, the Beck did even worse than the HAM-D in placebo-controlled trials, so that one can’t be the case. Or perhaps antidepressants work very well for some people, but just not for most people? That line of thinking was crushed too – the variability in scores for placebo was indistinguishable from the variability in scores in the treatment arms. (Note: a previous version of this study, by the same authors, found that there were significant differences, and was retracted because it was wrong. Since the authors originally came to the opposite result, suggesting some amount of researcher allegiance to the hypothesis, the negative result seems especially likely to be valid.)
Another line of cope is the idea that big placebo effects represent real healing, and that antidepressants should continue to be prescribed for their placebo effect alone. Unfortunately, a great deal of the “placebo effect” found in these studies is probably a result of poor methodology. In the field of dermatology, this is known as “eligibility creep” – researchers inflate scores at baseline in order to qualify subjects, and then don’t inflate the scores at later points of analysis. There does seem to be evidence that this occurs in antidepressant trials. Furthermore, antidepressant medications cause significant side effects, so even if we believed that placebo healing is real healing rather than the result of research bias and questionable research practices, such drugs would not be appropriate to prescribe for this effect.
Perhaps it shouldn’t be surprising that SSRIs in particular are not effective in treating depression, as every few years, someone points out that the popular serotonin hypothesis of depression is not substantiated by evidence. The most recent is a 2022 review, summarized here. The authors respond to common objections here. I have no reason to believe that this will be any more effective than similar efforts going back to the 1990s to debunk the serotonin hypothesis; the myth of serotonin seems as sticky and ineradicable as the myth of antidepressant efficacy.
What about Cognitive Behavioral Therapy? If antidepressants can’t be expected to produce clinically relevant relief from symptoms of depression, what about the most-touted “evidence-based” form of talk therapy? If you have read meta-analyses comparing CBT to “psychological placebo,” you may have been enormous effect sizes reported. A psychological placebo is something like treatment as usual, a waiting list, or some kind of vague “talking to a therapist,” not a real pill placebo. Even the aforementioned “Dance and Movement Therapy” achieved big effects sizes against psychological placebo that bordered on clinical significance. While I do not believe that placebo healing is real healing, the pill placebo control does seem to be something of a questionable research practice limiter. These authors give some suggestions why. I am not familiar with all possible methods of questionable research practices in therapy trials, but it does seem like it’s harder to cheat against a pill placebo compared to a psychological placebo.
When Cognitive Behavioral Therapy is up against pill placebo, the effect size, according to the most recent meta-analysis I could find, is a mere .22 when using the HAM-D. When using the self-report Beck Depression Inventory, the result is indistinguishable from zero and non-significant. As meager as the results for antidepressants are, the results for CBT are even worse. Researchers seem to think that subjects get a trivial amount better, but subjects themselves seem to feel no better compared to pill placebo.
You might imagine that there would be an outcry challenging this analysis, but I wasn’t able to find one. A typical write-up of this finding was the following:
CBT can benefit patients with severe depression, say researchers
…When compared with pill placebo, CBT led to greater symptom reduction on average by a standardized mean difference of -0.22 (95% confidence interval -0.42 to -0.02; P=-.03) on the Hamilton Rating Scale for Depression. The researchers said that this meant that the number needed to treat is 12 in typical cases of major depression, where the expected placebo response rates may be 30-50%. This would compare favorably, they said, with the number needed to treat (9) that can be expected in antidepressants, with an effect size of 0.31 over placebo.
The community seems to have just accepted this finding as meaning that CBT works, without apparently addressing the fact that the effect represents less than a two-point drop on a 52-point symptom scale, which is, as explained above, not clinically significant and probably not even clinically detectable.
One defense of CBT might be that, unlike antidepressants, at least talk therapy cannot be harmful. I am not sure I believe this. Although CBT is not approved for the treatment of major depression in bananas, my experience with CBT was initially promising: the hope that my bad emotions were caused by bad thoughts, and that deconstructing the bad thoughts would limit the occurrence of bad emotions. However, what I learned through a few weeks of CBT, deconstructing every bad thought and bad emotion, is that the frequency and intensity of bad emotions is not affected at all by reasoning. If anything, the thoughts that co-occurred with bad emotions got even more ridiculous. Without CBT, it might not have been clear that I had no control over the occurrence of bad emotions. This might be regarded by some as a harm. Initially, I’d suspected that the apparent large effect sizes for CBT were a result of subjects answering surveys differently – e.g. experiencing a pure bad emotion rather than identifying it as “guilt” – but apparently my hypothesis was wrong: it was bad controls all the time, and I had been insufficiently cynical.
I am also a bit surprised, given the sacred beliefs mentioned at the beginning, by the fact that the existence of CBT is not considered insulting. It is hard for me to distinguish the methodology of CBT and other talk therapy methodologies from the aforementioned troll “depression is a choice.” If it’s really a disease, how would it make sense for it to be treatable by thinking correctly instead of thinking wrong? But apparently most humans do not make this connection and hence do not thereby feel insulted.
An interesting rejoinder to the evidence that psychiatric treatments are not particularly effective is that very little medicine is actually effective. Harriet Hall, biting every bullet, titles her article “Most Patients Get No Benefit From Most Drugs.” Certainly, the problem of medicine generally not being effective is not limited to the field of psychiatry. But does that make it somehow excusable that the top treatments for depression cannot produce any clinically relevant effect? If I found out that all shoes tend to degrade into uselessness in two days, it wouldn’t make me feel a lot better to find out that hats also degrade into uselessness in two days.
If antidepressants and CBT are the best treatments available, and have no clinically significant effect on symptoms of depression, what “help” is reasonably available? If the “stigma and shame” preventing people from seeking mental health treatment disappeared overnight, and everyone got treatment – and this seems to have largely happened, as antidepressants and CBT are as popular as they have ever been – it seems unlikely to make any difference in outcome. If the best the field has to offer is a glorified placebo, perhaps it has no help to offer at all. If this is true in many fields of medicine, then the problem is multiplied rather than solved.
As a banana who lives among humans, I am naturally interested in humans, and in the social sciences they use to study themselves. This essay is my current response to the Thiel question: “What important truth do very few people agree with you on?” And my answer is that surveys are bullshit.
In the abstract, I think a lot of people would agree with me that surveys are bullshit. What I don’t think is widely known is how much “knowledge” is based on survey evidence, and what poor evidence it makes in the contexts in which it is used. The nutrition study that claims that eating hot chili peppers makes you live longer is based on surveys. The twin study about the heritability of joining a gang or carrying a gun is based on surveys of young people. The economics study claiming that long commutes reduce happiness is based on surveys, as are all studies of happiness, like the one that claims that people without a college degree are much less happy than they were in the 1970s. The study that claims that pornography is a substitute for marriage is based on surveys. That criminology statistic about domestic violence or sexual assault or drug use or the association of crime with personality factors is almost certainly based on surveys. (Violent crime studies and statistics are particularly likely to be based on extremely cursed instruments, especially the Conflict Tactics Scale, the Sexual Experiences Survey, and their descendants.) Medical studies of pain and fatigue rely on surveys. Almost every study of a psychiatric condition is based on surveys, even if an expert interviewer is taking the survey on the subject’s behalf (e.g. the Hamilton Depression Rating Scale). Many studies that purport to be about suicide are actually based on surveys of suicidal thoughts or behaviors. In the field of political science, election polls and elections themselves are surveys.
I have been trying to understand the “lexical hypothesis” of personality, and its modern descendant, the Five Factor Model of personality, for severalmonths. In that time, I have said some provocative things about the Big Five, and even some unkind things that I admit were unbecoming to a banana. Here, I wish to situate the Five Factor Model in the context of its historical development and modern use, and to demonstrate to the reader the surprising accomplishment that it represents for the field of psychology. Continue reading “The Ongoing Accomplishment of the Big Five”
It’s difficult to study words, because words are hard to see. Words are tools used in communication, and when communication is working, they disappear into invisibility.
One way to see words is to make a word jail: a list of problematic words ripped out of their contexts, so that they may be seen for themselves instead of hiding behind meanings.
Another way to see words freshly, to experience them as broken and therefore present, is to enter a new domain with its own unfamiliar jargon. Military basic training, rock climbing, sailing (whether Melville-era or contemporary), and weaving all require that novices take on a new jargon in order to get a grip on a new domain. The jargon enables the initiates to pick out important aspects of the world (in their bodies, in the natural environment, in the technology). With new words, they learn to identify newly-salient aspects of reality and communicate with others about them.Continue reading “Words Fail”
A literal banana has published a method for volunteer investigators of suspicious science, this month in the Journal of Lexical Crime. From the abstract:
Fact checking of scientific claims by lay volunteers, also known as recreational hostile fact checking or community-based science policing, is a growing hobby. A method for the evaluation of scientific claims by scientifically literate non-expert investigators is presented. The Extended Sniff Test, performed after an initial sniff test, uses the methods of Double Contextualization, Noun Abuse Assessment, and lay literature review, in addition to traditional literature review. As a case study, a suspicious paper is subjected to the Extended Sniff Test, and fails. A quick guide to the Extended Sniff Test is provided.